Page not found
Sorry, but the page you were trying to get to, does not exist. You may want to try searching this site using the sidebar or using our API Reference page to find what you were looking for.
Sorry, but the page you were trying to get to, does not exist. You may want to try searching this site using the sidebar or using our API Reference page to find what you were looking for.
Machine learning algorithms using matrices.
Function of a surface with two hills
Minimizes a continuous differentiable multivariate function
Linear regression cost and gradient function with regularization from Andrew Ng’s course (ex3)
The same cost function, implemented with operators from Matrex.Operators module
Cost function for neural network with one hidden layer
Predict labels for the featurex with pre-trained neuron coefficients theta1 and theta2
Run logistic regression one-vs-all MNIST digits recognition in parallel
Run neural network with one hidden layer
Computes sigmoid gradinet for the given matrix
Function of a surface with two hills.
Minimizes a continuous differentiable multivariate function.
Ported to Elixir from Octave version, found in Andre Ng’s course, (c) Carl Edward Rasmussen.
f — cost function, that takes two paramteters: current version of x and fParams. For example, lr_cost_fun/2.
x — vector of parameters, which we try to optimize,
so that cost function returns the minimum value.
fParams — this value is passed as the second parameter to the cost function.
length — number of iterations to perform.
Returns column matrix of found solutions, list of cost function values and number of iterations used.
Starting point is given by x (D by 1), and the function f, must
return a function value and a vector of partial derivatives. The Polack-Ribiere
flavour of conjugate gradients is used to compute search directions,
and a line search using quadratic and cubic polynomial approximations and the
Wolfe-Powell stopping criteria is used together with the slope ratio method
for guessing initial step sizes. Additionally a bunch of checks are made to
make sure that exploration is taking place and that extrapolation will not
be unboundedly large.
lr_cost_fun( Matrex.t(), {Matrex.t(), Matrex.t(), number(), non_neg_integer()}, pos_integer() ) :: {float(), Matrex.t()}
Linear regression cost and gradient function with regularization from Andrew Ng’s course (ex3).
Computes the cost of using theta as the parameter for regularized logistic regression and the
gradient of the cost w.r.t. to the parameters.
Compatible with fmincg/4 algorithm from thise module.
theta — parameters, to compute cost for
X — training data input.
y — training data output.
lambda — regularization parameter.
The same cost function, implemented with operators from Matrex.Operators module.
Works 2 times slower, than standard implementation. But it’s a way more readable.
nn_cost_fun( Matrex.t(), {pos_integer(), pos_integer(), pos_integer(), Matrex.t(), Matrex.t(), number()}, pos_integer() ) :: {number(), Matrex.t()}
Cost function for neural network with one hidden layer.
Does delta computation in parallel.
Ported from Andrew Ng’s course, ex4.
Predict labels for the featurex with pre-trained neuron coefficients theta1 and theta2.
Run logistic regression one-vs-all MNIST digits recognition in parallel.
Run neural network with one hidden layer.
Computes sigmoid gradinet for the given matrix.
g = sigmoid(X) * (1 - sigmoid(X))Overrides Kernel math operators and adds common math functions shortcuts for use with matrices. Use with caution.
iex> import IEx.Helpers, except: [t: 1] # Only in iex, conflicts with transpose function
iex> import Matrex.Operators
iex> import Kernel, except: [-: 1, +: 2, -: 2, *: 2, /: 2, <|>: 2]
iex> import Matrex
iex> m = random(5, 3)
#Matrex[5×3]
┌ ┐
│ 0.51502 0.03132 0.94185 │
│ 0.49434 0.93887 0.91102 │
│ 0.70671 0.89428 0.28817 │
│ 0.23771 0.37695 0.38214 │
│ 0.37221 0.34008 0.19615 │
└ ┘
iex> m * t(m) / eye(5) |> sigmoid()
#Matrex[5×5]
┌ ┐
│ 0.76012 1.0 1.0 1.0 1.0 │
│ 1.0 0.87608 1.0 1.0 1.0 │
│ 1.0 1.0 0.79935 1.0 1.0 │
│ 1.0 1.0 1.0 0.58531 1.0 │
│ 1.0 1.0 1.0 1.0 0.57265 │
└ ┘Element-wise matrices multiplication. The same as Matrex.multiply/2
Applies C language abs(x) to each element of the matrix. See Matrex.apply/2
Applies C language acos(x) to each element of the matrix. See Matrex.apply/2
Applies C language acosh(x) to each element of the matrix. See Matrex.apply/2
Applies C language asin(x) to each element of the matrix. See Matrex.apply/2
Applies C language asinh(x) to each element of the matrix. See Matrex.apply/2
Applies C language atan(x) to each element of the matrix. See Matrex.apply/2
Applies C language atanh(x) to each element of the matrix. See Matrex.apply/2
Applies C language cbrt(x) to each element of the matrix. See Matrex.apply/2
Applies C language ceil(x) to each element of the matrix. See Matrex.apply/2
Applies C language cos(x) to each element of the matrix. See Matrex.apply/2
Applies C language cosh(x) to each element of the matrix. See Matrex.apply/2
Applies C language erf(x) to each element of the matrix. See Matrex.apply/2
Applies C language erfc(x) to each element of the matrix. See Matrex.apply/2
Applies C language exp(x) to each element of the matrix. See Matrex.apply/2
Applies C language exp2(x) to each element of the matrix. See Matrex.apply/2
Applies C language expm1(x) to each element of the matrix. See Matrex.apply/2
Applies C language floor(x) to each element of the matrix. See Matrex.apply/2
Applies C language lgamma(x) to each element of the matrix. See Matrex.apply/2
Applies C language log(x) to each element of the matrix. See Matrex.apply/2
Applies C language log2(x) to each element of the matrix. See Matrex.apply/2
Applies C language round(x) to each element of the matrix. See Matrex.apply/2
Applies C language sigmoid(x) to each element of the matrix. See Matrex.apply/2
Applies C language sin(x) to each element of the matrix. See Matrex.apply/2
Applies C language sinh(x) to each element of the matrix. See Matrex.apply/2
Applies C language sqrt(x) to each element of the matrix. See Matrex.apply/2
Transpose a matrix
Applies C language tan(x) to each element of the matrix. See Matrex.apply/2
Applies C language tanh(x) to each element of the matrix. See Matrex.apply/2
Applies C language tgamma(x) to each element of the matrix. See Matrex.apply/2
Applies C language truncate(x) to each element of the matrix. See Matrex.apply/2
Element-wise matrices multiplication. The same as Matrex.multiply/2
Applies C language abs(x) to each element of the matrix. See Matrex.apply/2
Applies C language acos(x) to each element of the matrix. See Matrex.apply/2
Applies C language acosh(x) to each element of the matrix. See Matrex.apply/2
Applies C language asin(x) to each element of the matrix. See Matrex.apply/2
Applies C language asinh(x) to each element of the matrix. See Matrex.apply/2
Applies C language atan(x) to each element of the matrix. See Matrex.apply/2
Applies C language atanh(x) to each element of the matrix. See Matrex.apply/2
Applies C language cbrt(x) to each element of the matrix. See Matrex.apply/2
Applies C language ceil(x) to each element of the matrix. See Matrex.apply/2
Applies C language cos(x) to each element of the matrix. See Matrex.apply/2
Applies C language cosh(x) to each element of the matrix. See Matrex.apply/2
Applies C language erf(x) to each element of the matrix. See Matrex.apply/2
Applies C language erfc(x) to each element of the matrix. See Matrex.apply/2
Applies C language exp(x) to each element of the matrix. See Matrex.apply/2
Applies C language exp2(x) to each element of the matrix. See Matrex.apply/2
Applies C language expm1(x) to each element of the matrix. See Matrex.apply/2
Applies C language floor(x) to each element of the matrix. See Matrex.apply/2
Applies C language lgamma(x) to each element of the matrix. See Matrex.apply/2
Applies C language log(x) to each element of the matrix. See Matrex.apply/2
Applies C language log2(x) to each element of the matrix. See Matrex.apply/2
See Matrex.square/1
Applies C language round(x) to each element of the matrix. See Matrex.apply/2
Applies C language sigmoid(x) to each element of the matrix. See Matrex.apply/2
Applies C language sin(x) to each element of the matrix. See Matrex.apply/2
Applies C language sinh(x) to each element of the matrix. See Matrex.apply/2
Applies C language sqrt(x) to each element of the matrix. See Matrex.apply/2
Transpose a matrix.
Applies C language tan(x) to each element of the matrix. See Matrex.apply/2
Applies C language tanh(x) to each element of the matrix. See Matrex.apply/2
Applies C language tgamma(x) to each element of the matrix. See Matrex.apply/2
Applies C language truncate(x) to each element of the matrix. See Matrex.apply/2
Performs fast operations on matrices using native C code and CBLAS library.
Access behaviour is partly implemented for Matrex, so you can do:
iex> m = Matrex.magic(3)
#Matrex[3×3]
┌ ┐
│ 8.0 1.0 6.0 │
│ 3.0 5.0 7.0 │
│ 4.0 9.0 2.0 │
└ ┘
iex> m[2][3]
7.0Or even:
iex> m[1..2]
#Matrex[2×3]
┌ ┐
│ 8.0 1.0 6.0 │
│ 3.0 5.0 7.0 │
└ ┘There are also several shortcuts for getting dimensions of matrix:
iex> m[:rows]
3
iex> m[:size]
{3, 3}calculating maximum value of the whole matrix:
iex> m[:max]
9.0or just one of it’s rows:
iex> m[2][:max]
7.0calculating one-based index of the maximum element for the whole matrix:
iex> m[:argmax]
8and a row:
iex> m[2][:argmax]
3Matrex implements Inspect and looks nice in your console:
Matrex.Operators module redefines Kernel math operators (+, -, *, / <|>) and
defines some convenience functions, so you can write calculations code in more natural way.
It should be used with great caution. We suggest using it only inside specific functions
and only for increased readability, because using Matrex module functions, especially
ones which do two or more operations at one call, are 2-3 times faster.
def lr_cost_fun_ops(%Matrex{} = theta, {%Matrex{} = x, %Matrex{} = y, lambda} = _params)
when is_number(lambda) do
# Turn off original operators
import Kernel, except: [-: 1, +: 2, -: 2, *: 2, /: 2, <|>: 2]
import Matrex.Operators
import Matrex
m = y[:rows]
h = sigmoid(x * theta)
l = ones(size(theta)) |> set(1, 1, 0.0)
j = (-t(y) * log(h) - t(1 - y) * log(1 - h) + lambda / 2 * t(l) * pow2(theta)) / m
grad = (t(x) * (h - y) + (theta <|> l) * lambda) / m
{scalar(j), grad}
endThe same function, coded with module methods calls (2.5 times faster):
def lr_cost_fun(%Matrex{} = theta, {%Matrex{} = x, %Matrex{} = y, lambda} = _params)
when is_number(lambda) do
m = y[:rows]
h = Matrex.dot_and_apply(x, theta, :sigmoid)
l = Matrex.ones(theta[:rows], theta[:cols]) |> Matrex.set(1, 1, 0)
regularization =
Matrex.dot_tn(l, Matrex.square(theta))
|> Matrex.scalar()
|> Kernel.*(lambda / (2 * m))
j =
y
|> Matrex.dot_tn(Matrex.apply(h, :log), -1)
|> Matrex.subtract(
Matrex.dot_tn(
Matrex.subtract(1, y),
Matrex.apply(Matrex.subtract(1, h), :log)
)
)
|> Matrex.scalar()
|> (fn
:nan -> :nan
x -> x / m + regularization
end).()
grad =
x
|> Matrex.dot_tn(Matrex.subtract(h, y))
|> Matrex.add(Matrex.multiply(theta, l), 1.0, lambda)
|> Matrex.divide(m)
{j, grad}
endMatrex implements Enumerable, so, all kinds of Enum functions are applicable:
iex> Enum.member?(m, 2.0)
true
iex> Enum.count(m)
9
iex> Enum.sum(m)
45For functions, that exist both in Enum and in Matrex it’s preferred to use Matrex
version, beacuse it’s usually much, much faster. I.e., for 1 000 x 1 000 matrix Matrex.sum/1
and Matrex.to_list/1 are 438 and 41 times faster, respectively, than their Enum counterparts.
You can save/load matrix with native binary file format (extra fast) and CSV (slow, especially on large matrices).
Matrex CSV format is compatible with GNU Octave CSV output, so you can use it to exchange data between two systems.
iex> Matrex.random(5) |> Matrex.save("rand.mtx")
:ok
iex> Matrex.load("rand.mtx")
#Matrex[5×5]
┌ ┐
│ 0.05624 0.78819 0.29995 0.25654 0.94082 │
│ 0.50225 0.22923 0.31941 0.3329 0.78058 │
│ 0.81769 0.66448 0.97414 0.08146 0.21654 │
│ 0.33411 0.59648 0.24786 0.27596 0.09082 │
│ 0.18673 0.18699 0.79753 0.08101 0.47516 │
└ ┘
iex> Matrex.magic(5) |> Matrex.divide(Matrex.eye(5)) |> Matrex.save("nan.csv")
:ok
iex> Matrex.load("nan.csv")
#Matrex[5×5]
┌ ┐
│ 16.0 ∞ ∞ ∞ ∞ │
│ ∞ 4.0 ∞ ∞ ∞ │
│ ∞ ∞ 12.0 ∞ ∞ │
│ ∞ ∞ ∞ 25.0 ∞ │
│ ∞ ∞ ∞ ∞ 8.0 │
└ ┘Float special values, like :nan and :inf live well inside matrices,
can be loaded from and saved to files.
But when getting them into Elixir they are transferred to :nan,:inf and :neg_inf atoms,
because BEAM does not accept special values as valid floats.
iex> m = Matrex.eye(3)
#Matrex[3×3]
┌ ┐
│ 1.0 0.0 0.0 │
│ 0.0 1.0 0.0 │
│ 0.0 0.0 1.0 │
└ ┘
iex> n = Matrex.divide(m, Matrex.zeros(3))
#Matrex[3×3]
┌ ┐
│ ∞ NaN NaN │
│ NaN ∞ NaN │
│ NaN NaN ∞ │
└ ┘
iex> n[1][1]
:inf
iex> n[1][2]
:nanAdds scalar to matrix
Adds two matrices or scalar to each element of matrix. NIF
Applies given function to each element of the matrix and returns the matrex of results. NIF
Applies function to elements of two matrices and returns matrix of function results
Returns one-based index of the biggest element. NIF
Get element of a matrix at given one-based (row, column) position
Get column of matrix as matrix (vector) in matrex form. One-based
Get column of matrix as list of floats. One-based, NIF
Concatenate list of matrices along columns
Concatenate two matrices along rows or columns. NIF
Checks if given element exists in the matrix
Divides two matrices element-wise or matrix by scalar or scalar by matrix. NIF through find/2
Matrix multiplication. NIF, via cblas_sgemm()
Matrix multiplication with addition of third matrix. NIF, via cblas_sgemm()
Computes dot product of two matrices, then applies math function to each element of the resulting matrix
Matrix multiplication where the second matrix needs to be transposed. NIF, via cblas_sgemm()
Matrix dot multiplication where the first matrix needs to be transposed. NIF, via cblas_sgemm()
Create eye (identity) square matrix of given size
Create square matrix filled with given value. Inlined
Create matrix filled with given value. NIF
Find position of the first occurence of the given value in the matrix. NIF
Return first element of a matrix
Prints monochrome or color heatmap of the matrix to the console
An alias for eye/1
Returns list of all rows of a matrix as single-row matrices
Returns range of rows of a matrix as list of 1-row matrices
Load matrex from file
Creates “magic” n*n matrix, where sums of all dimensions are equal
Maximum element in a matrix. NIF
Returns maximum finite element of a matrex. NIF
Minimum element in a matrix. NIF
Returns minimum finite element of a matrex. NIF
Elementwise multiplication of two matrices or matrix and a scalar. NIF
Negates each element of the matrix. NIF
Creates new matrix from list of lists or text representation (compatible with MathLab/Octave)
Creates new matrix with values provided by the given function
Bring all values of matrix into [0, 1] range. NIF
Create matrex of ones of square dimensions or consuming output of size/1 function
Create matrix filled with ones
Prints matrix to the console
Create square matrix of random floats
Create matrix of random floats in [0, 1] range. NIF
Reshapes list of values into a matrix of given size or changes the shape of existing matrix
Resize matrix by scaling its dimenson with scale. NIF
Get row of matrix as matrix (vector) in matrex form. One-based
Return matrix row as list by one-based index
Saves matrex into file
Transfer one-element matrix to a scalar value
Set element of matrix at the specified position (one-based) to new value
Set column of a matrix to the values from the given 1-column matrix. NIF
Return size of matrix as {rows, cols}
Produces element-wise squared matrix. NIF through multiply/4
Returns submatrix for a given matrix. NIF
Subtracts two matrices or matrix from scalar element-wise. NIF
Subtracts the second matrix or scalar from the first. Inlined
Sums all elements. NIF
Convert any matrix m×n to a column matrix (m*n)×1
Converts to flat list. NIF
Converts to list of lists. NIF
Convert any matrix m×n to a row matrix 1×(m*n)
Transposes a matrix. NIF
Updates the element at the given position in matrix with function
Create square matrix of size size rows × size columns, filled with zeros. Inlined
Create matrix of zeros of the specified size. NIF, using memset()
Adds scalar to matrix.
See Matrex.add/4 for details.
Adds two matrices or scalar to each element of matrix. NIF.
Can optionally scale any of the two matrices.
C = αA + βB
Raises ErlangError if matrices’ sizes do not match.
iex> Matrex.add(Matrex.new([[1,2,3],[4,5,6]]), Matrex.new([[7,8,9],[10,11,12]]))
#Matrex[2×3]
┌ ┐
│ 8.0 10.0 12.0 │
│ 14.0 16.0 18.0 │
└ ┘Adding with scalar:
iex> m = Matrex.magic(3)
#Matrex[3×3]
┌ ┐
│ 8.0 1.0 6.0 │
│ 3.0 5.0 7.0 │
│ 4.0 9.0 2.0 │
└ ┘
iex> Matrex.add(m, 1)
#Matrex[3×3]
┌ ┐
│ 9.0 2.0 7.0 │
│ 4.0 6.0 8.0 │
│ 5.0 10.0 3.0 │
└ ┘With scaling each matrix:
iex> Matrex.add(Matrex.new("1 2 3; 4 5 6"), Matrex.new("3 2 1; 6 5 4"), 2.0, 3.0)
#Matrex[2×3]
┌ ┐
│ 11.0 10.0 9.0 │
│ 26.0 25.0 24.0 │
└ ┘Applies given function to each element of the matrix and returns the matrex of results. NIF.
If second argument is an atom, then applies C language math function.
iex> Matrex.magic(5) |> Matrex.apply(:sigmoid)
#Matrex[5×5]
┌ ┐
│-0.95766-0.53283 0.28366 0.7539 0.13674 │
│-0.99996-0.65364 0.96017 0.90745 0.40808 │
│-0.98999-0.83907 0.84385 0.9887-0.54773 │
│-0.91113 0.00443 0.66032 0.9912-0.41615 │
│-0.75969-0.27516 0.42418 0.5403 -0.1455 │
└ ┘The following math functions from C
:exp, :exp2, :sigmoid, :expm1, :log, :log2, :sqrt, :cbrt, :ceil, :floor, :truncate, :round,
:abs, :sin, :cos, :tan, :asin, :acos, :atan, :sinh, :cosh, :tanh, :asinh, :acosh, :atanh,
:erf, :erfc, :tgamma, :lgammIf second argument is a function that takes one argument, then this function receives the element of the matrix.
iex> Matrex.magic(5) |> Matrex.apply(&:math.cos/1)
#Matrex[5×5]
┌ ┐
│-0.95766-0.53283 0.28366 0.7539 0.13674 │
│-0.99996-0.65364 0.96017 0.90745 0.40808 │
│-0.98999-0.83907 0.84385 0.9887-0.54773 │
│-0.91113 0.00443 0.66032 0.9912-0.41615 │
│-0.75969-0.27516 0.42418 0.5403 -0.1455 │
└ ┘If second argument is a function that takes two arguments, then this function receives the element of the matrix and its one-based index.
iex> Matrex.ones(5) |> Matrex.apply(fn val, index -> val + index end)
#Matrex[5×5]
┌ ┐
│ 2.0 3.0 4.0 5.0 6.0 │
│ 7.0 8.0 9.0 10.0 11.0 │
│ 12.0 13.0 14.0 15.0 16.0 │
│ 17.0 18.0 19.0 20.0 21.0 │
│ 22.0 23.0 24.0 25.0 26.0 │
└ ┘If second argument is a function that takes three arguments, then this function receives the element of the matrix one-based row index and one-based column index of the element.
iex> Matrex.ones(5) |> Matrex.apply(fn val, row, col -> val + row + col end)
#Matrex[5×5]
┌ ┐
│ 3.0 4.0 5.0 6.0 7.0 │
│ 4.0 5.0 6.0 7.0 8.0 │
│ 5.0 6.0 7.0 8.0 9.0 │
│ 6.0 7.0 8.0 9.0 10.0 │
│ 7.0 8.0 9.0 10.0 11.0 │
└ ┘Applies function to elements of two matrices and returns matrix of function results.
Matrices must be of the same size.
iex(11)> Matrex.apply(Matrex.random(5), Matrex.random(5), fn x1, x2 -> min(x1, x2) end)
#Matrex[5×5]
┌ ┐
│ 0.02025 0.15055 0.69177 0.08159 0.07237 │
│ 0.03252 0.14805 0.03627 0.1733 0.58721 │
│ 0.10865 0.49192 0.12166 0.0573 0.66522 │
│ 0.13642 0.23838 0.14403 0.57151 0.12359 │
│ 0.12877 0.12745 0.10933 0.27281 0.35957 │
└ ┘Returns one-based index of the biggest element. NIF.
There is also matrex[:argmax] shortcut for this function.
iex> m = Matrex.magic(3)
#Matrex[3×3]
┌ ┐
│ 8.0 1.0 6.0 │
│ 3.0 5.0 7.0 │
│ 4.0 9.0 2.0 │
└ ┘
iex> Matrex.argmax(m)
7Get element of a matrix at given one-based (row, column) position.
Negative or out of bound indices will raise an exception.
iex> m = Matrex.magic(3)
#Matrex[3×3]
┌ ┐
│ 8.0 1.0 6.0 │
│ 3.0 5.0 7.0 │
│ 4.0 9.0 2.0 │
└ ┘
iex> Matrex.at(m, 3, 2)
9.0You can use Access behaviour square brackets for the same purpose,
but it will be slower:
iex> m[3][2]
9.0Get column of matrix as matrix (vector) in matrex form. One-based.
iex> m = Matrex.magic(3)
#Matrex[3×3]
┌ ┐
│ 8.0 1.0 6.0 │
│ 3.0 5.0 7.0 │
│ 4.0 9.0 2.0 │
└ ┘
iex> Matrex.column(m, 2)
#Matrex[3×1]
┌ ┐
│ 1.0 │
│ 5.0 │
│ 9.0 │
└ ┘Get column of matrix as list of floats. One-based, NIF.
iex> m = Matrex.magic(3)
#Matrex[3×3]
┌ ┐
│ 8.0 1.0 6.0 │
│ 3.0 5.0 7.0 │
│ 4.0 9.0 2.0 │
└ ┘
iex> Matrex.column_to_list(m, 3)
[6.0, 7.0, 2.0]Concatenate list of matrices along columns.
The number of rows must be equal.
iex> Matrex.concat([Matrex.fill(2, 0), Matrex.fill(2, 1), Matrex.fill(2, 2)]) #Matrex[2×6]
┌ ┐
│ 0.0 0.0 1.0 1.0 2.0 2.0 │
│ 0.0 0.0 1.0 1.0 2.0 2.0 │
└ ┘Concatenate two matrices along rows or columns. NIF.
The number of rows or columns must be equal.
iex> m1 = Matrex.new([[1, 2, 3], [4, 5, 6]])
#Matrex[2×3]
┌ ┐
│ 1.0 2.0 3.0 │
│ 4.0 5.0 6.0 │
└ ┘
iex> m2 = Matrex.new([[7, 8, 9], [10, 11, 12]])
#Matrex[2×3]
┌ ┐
│ 7.0 8.0 9.0 │
│ 10.0 11.0 12.0 │
└ ┘
iex> Matrex.concat(m1, m2)
#Matrex[2×6]
┌ ┐
│ 1.0 2.0 3.0 7.0 8.0 9.0 │
│ 4.0 5.0 6.0 10.0 11.0 12.0 │
└ ┘
iex> Matrex.concat(m1, m2, :rows)
#Matrex[4×3]
┌ ┐
│ 1.0 2.0 3.0 │
│ 4.0 5.0 6.0 │
│ 7.0 8.0 9.0 │
│ 10.0 11.0 12.0 │
└ ┘Checks if given element exists in the matrix.
iex> m = Matrex.new("1 NaN 3; Inf 10 23")
#Matrex[2×3]
┌ ┐
│ 1.0 NaN 3.0 │
│ ∞ 10.0 23.0 │
└ ┘
iex> Matrex.contains?(m, 1.0)
true
iex> Matrex.contains?(m, :nan)
true
iex> Matrex.contains?(m, 9)
falseDivides two matrices element-wise or matrix by scalar or scalar by matrix. NIF through find/2.
Raises ErlangError if matrices’ sizes do not match.
iex> Matrex.new([[10, 20, 25], [8, 9, 4]])
...> |> Matrex.divide(Matrex.new([[5, 10, 5], [4, 3, 4]]))
#Matrex[2×3]
┌ ┐
│ 2.0 2.0 5.0 │
│ 2.0 3.0 1.0 │
└ ┘
iex> Matrex.new([[10, 20, 25], [8, 9, 4]])
...> |> Matrex.divide(2)
#Matrex[2×3]
┌ ┐
│ 5.0 10.0 12.5 │
│ 4.0 4.5 2.0 │
└ ┘
iex> Matrex.divide(100, Matrex.new([[10, 20, 25], [8, 16, 4]]))
#Matrex[2×3]
┌ ┐
│ 10.0 5.0 4.0 │
│ 12.5 6.25 25.0 │
└ ┘Matrix multiplication. NIF, via cblas_sgemm().
Number of columns of the first matrix must be equal to the number of rows of the second matrix.
Raises ErlangError if matrices’ sizes do not match.
iex> Matrex.new([[1, 2, 3], [4, 5, 6]]) |>
...> Matrex.dot(Matrex.new([[1, 2], [3, 4], [5, 6]]))
#Matrex[2×2]
┌ ┐
│ 22.0 28.0 │
│ 49.0 64.0 │
└ ┘Matrix multiplication with addition of third matrix. NIF, via cblas_sgemm().
Raises ErlangError if matrices’ sizes do not match.
iex> Matrex.new([[1, 2, 3], [4, 5, 6]]) |>
...> Matrex.dot_and_add(Matrex.new([[1, 2], [3, 4], [5, 6]]), Matrex.new([[1, 2], [3, 4]]))
#Matrex[2×2]
┌ ┐
│ 23.0 30.0 │
│ 52.0 68.0 │
└ ┘Computes dot product of two matrices, then applies math function to each element of the resulting matrix.
iex> Matrex.new([[1, 2, 3], [4, 5, 6]]) |>
...> Matrex.dot_and_apply(Matrex.new([[1, 2], [3, 4], [5, 6]]), :sqrt)
#Matrex[2×2]
┌ ┐
│ 4.69042 5.2915 │
│ 7.0 8.0 │
└ ┘Matrix multiplication where the second matrix needs to be transposed. NIF, via cblas_sgemm().
Raises ErlangError if matrices’ sizes do not match.
iex> Matrex.new([[1, 2, 3], [4, 5, 6]]) |>
...> Matrex.dot_nt(Matrex.new([[1, 3, 5], [2, 4, 6]]))
#Matrex[2×2]
┌ ┐
│ 22.0 28.0 │
│ 49.0 64.0 │
└ ┘Matrix dot multiplication where the first matrix needs to be transposed. NIF, via cblas_sgemm().
The result is multiplied by scalar alpha.
Raises ErlangError if matrices’ sizes do not match.
iex> Matrex.new([[1, 4], [2, 5], [3, 6]]) |>
...> Matrex.dot_tn(Matrex.new([[1, 2], [3, 4], [5, 6]]))
#Matrex[2×2]
┌ ┐
│ 22.0 28.0 │
│ 49.0 64.0 │
└ ┘Create eye (identity) square matrix of given size.
iex> Matrex.eye(3)
#Matrex[3×3]
┌ ┐
│ 1.0 0.0 0.0 │
│ 0.0 1.0 0.0 │
│ 0.0 0.0 1.0 │
└ ┘
iex> Matrex.eye(3, 2.95)
#Matrex[3×3]
┌ ┐
│ 2.95 0.0 0.0 │
│ 0.0 2.95 0.0 │
│ 0.0 0.0 2.95 │
└ ┘Create square matrix filled with given value. Inlined.
iex> Matrex.fill(3, 55)
#Matrex[3×3]
┌ ┐
│ 33.0 33.0 33.0 │
│ 33.0 33.0 33.0 │
│ 33.0 33.0 33.0 │
└ ┘Create matrix filled with given value. NIF.
iex> Matrex.fill(4,3, 55)
#Matrex[4×3]
┌ ┐
│ 55.0 55.0 55.0 │
│ 55.0 55.0 55.0 │
│ 55.0 55.0 55.0 │
│ 55.0 55.0 55.0 │
└ ┘Find position of the first occurence of the given value in the matrix. NIF.
Returns {row, column} tuple or nil, if nothing was found. One-based.
Prints monochrome or color heatmap of the matrix to the console.
Supports 8, 256 and 16mln of colors terminals. Monochrome on 256 color palette is the default.
type can be :mono8, :color8, :mono256, :color256, :mono24bit and :color24bit.
Special float values, like infinity and not-a-number are marked with contrast colors on the map.
:at — positions heatmap at the specified {row, col} position inside terminal.
:title — sets the title of the heatmap.



An alias for eye/1.
Returns list of all rows of a matrix as single-row matrices.
iex> m = Matrex.reshape(1..6, 3, 2)
#Matrex[6×2]
┌ ┐
│ 1.0 2.0 │
│ 3.0 4.0 │
│ 5.0 6.0 │
└ ┘
iex> Matrex.list_of_rows(m)
[#Matrex[1×2]
┌ ┐
│ 1.0 2.0 │
└ ┘,
#Matrex[1×2]
┌ ┐
│ 3.0 4.0 │
└ ┘,
#Matrex[1×2]
┌ ┐
│ 5.0 6.0 │
└ ┘]Returns range of rows of a matrix as list of 1-row matrices.
iex> m = Matrex.reshape(1..12, 6, 2)
#Matrex[6×2]
┌ ┐
│ 1.0 2.0 │
│ 3.0 4.0 │
│ 5.0 6.0 │
│ 7.0 8.0 │
│ 9.0 10.0 │
│ 11.0 12.0 │
└ ┘
iex> Matrex.list_of_rows(m, 2..4)
[#Matrex[1×2]
┌ ┐
│ 3.0 4.0 │
└ ┘,
#Matrex[1×2]
┌ ┐
│ 5.0 6.0 │
└ ┘,
#Matrex[1×2]
┌ ┐
│ 7.0 8.0 │
└ ┘]Load matrex from file.
.csv and .mtx (binary) formats are supported.
iex> Matrex.load("test/matrex.csv")
#Matrex[5×4]
┌ ┐
│ 0.0 4.8e-4-0.00517-0.01552 │
│-0.01616-0.01622 -0.0161-0.00574 │
│ 6.8e-4 0.0 0.0 0.0 │
│ 0.0 0.0 0.0 0.0 │
│ 0.0 0.0 0.0 0.0 │
└ ┘Creates “magic” n*n matrix, where sums of all dimensions are equal.
iex> Matrex.magic(5)
#Matrex[5×5]
┌ ┐
│ 16.0 23.0 5.0 7.0 14.0 │
│ 22.0 4.0 6.0 13.0 20.0 │
│ 3.0 10.0 12.0 19.0 21.0 │
│ 9.0 11.0 18.0 25.0 2.0 │
│ 15.0 17.0 24.0 1.0 8.0 │
└ ┘Maximum element in a matrix. NIF.
iex> m = Matrex.magic(5)
#Matrex[5×5]
┌ ┐
│ 16.0 23.0 5.0 7.0 14.0 │
│ 22.0 4.0 6.0 13.0 20.0 │
│ 3.0 10.0 12.0 19.0 21.0 │
│ 9.0 11.0 18.0 25.0 2.0 │
│ 15.0 17.0 24.0 1.0 8.0 │
└ ┘
iex> Matrex.max(m)
25.0
iex> Matrex.reshape([1, 2, :inf, 4, 5, 6], 2, 3) |> max()
:infReturns maximum finite element of a matrex. NIF.
Used on matrices which may contain infinite values.
iex>Matrex.reshape([1, 2, :inf, 3, :nan, 5], 3, 2) |> Matrex.max_finite()
5.0Minimum element in a matrix. NIF.
iex> m = Matrex.magic(5)
#Matrex[5×5]
┌ ┐
│ 16.0 23.0 5.0 7.0 14.0 │
│ 22.0 4.0 6.0 13.0 20.0 │
│ 3.0 10.0 12.0 19.0 21.0 │
│ 9.0 11.0 18.0 25.0 2.0 │
│ 15.0 17.0 24.0 1.0 8.0 │
└ ┘
iex> Matrex.min(m)
1.0
iex> Matrex.reshape([1, 2, :neg_inf, 4, 5, 6], 2, 3) |> max()
:neg_infReturns minimum finite element of a matrex. NIF.
Used on matrices which may contain infinite values.
iex>Matrex.reshape([1, 2, :neg_inf, 3, 4, 5], 3, 2) |> Matrex.min_finite()
1.0Elementwise multiplication of two matrices or matrix and a scalar. NIF.
Raises ErlangError if matrices’ sizes do not match.
iex> Matrex.new([[1, 2, 3], [4, 5, 6]]) |>
...> Matrex.multiply(Matrex.new([[5, 2, 1], [3, 4, 6]]))
#Matrex[2×3]
┌ ┐
│ 5.0 4.0 3.0 │
│ 12.0 20.0 36.0 │
└ ┘
iex> Matrex.new([[1, 2, 3], [4, 5, 6]]) |> Matrex.multiply(2)
#Matrex[2×3]
┌ ┐
│ 2.0 4.0 6.0 │
│ 8.0 10.0 12.0 │
└ ┘Negates each element of the matrix. NIF.
iex> Matrex.new([[1, 2, 3], [4, 5, 6]]) |> Matrex.neg()
#Matrex[2×3]
┌ ┐
│ -1.0 -2.0 -3.0 │
│ -4.0 -5.0 -6.0 │
└ ┘Creates new matrix from list of lists or text representation (compatible with MathLab/Octave).
List of lists can contain other matrices, which are concatenated in one.
iex> Matrex.new([[1, 2, 3], [4, 5, 6]])
#Matrex[2×3]
┌ ┐
│ 1.0 2.0 3.0 │
│ 4.0 5.0 6.0 │
└ ┘
iex> Matrex.new([[Matrex.fill(2, 1.0), Matrex.fill(2, 3, 2.0)],
...> [Matrex.fill(1, 2, 3.0), Matrex.fill(1, 3, 4.0)]])
#Matrex[5×5]
┌ ┐
│ 1.0 1.0 2.0 2.0 2.0 │
│ 1.0 1.0 2.0 2.0 2.0 │
│ 3.0 3.0 4.0 4.0 4.0 │
└ ┘
iex> Matrex.new("1;0;1;0;1")
#Matrex[5×1]
┌ ┐
│ 1.0 │
│ 0.0 │
│ 1.0 │
│ 0.0 │
│ 1.0 │
└ ┘
iex> Matrex.new("""
...> 1.00000 0.10000 0.60000 1.10000
...> 1.00000 0.20000 0.70000 1.20000
...> 1.00000 NaN 0.80000 1.30000
...> Inf 0.40000 0.90000 1.40000
...> 1.00000 0.50000 NegInf 1.50000
...> """)
#Matrex[5×4]
┌ ┐
│ 1.0 0.1 0.6 1.1 │
│ 1.0 0.2 0.7 1.2 │
│ 1.0 NaN 0.8 1.3 │
│ ∞ 0.4 0.9 1.4 │
│ 1.0 0.5 -∞ 1.5 │
└ ┘Creates new matrix with values provided by the given function.
If function accepts two arguments one-based row and column index of each element are passed to it.
iex> Matrex.new(3, 3, fn -> :rand.uniform() end)
#Matrex[3×3]
┌ ┐
│ 0.45643 0.91533 0.25332 │
│ 0.29095 0.21241 0.9776 │
│ 0.42451 0.05422 0.92863 │
└ ┘
iex> Matrex.new(3, 3, fn row, col -> row*col end)
#Matrex[3×3]
┌ ┐
│ 1.0 2.0 3.0 │
│ 2.0 4.0 6.0 │
│ 3.0 6.0 9.0 │
└ ┘Bring all values of matrix into [0, 1] range. NIF.
Where 0 corresponds to the minimum value of the matrix, and 1 — to the maxixmim.
iex> m = Matrex.reshape(1..9, 3, 3)
#Matrex[3×3]
┌ ┐
│ 1.0 2.0 3.0 │
│ 4.0 5.0 6.0 │
│ 7.0 8.0 9.0 │
└ ┘
iex> Matrex.normalize(m)
#Matrex[3×3]
┌ ┐
│ 0.0 0.125 0.25 │
│ 0.375 0.5 0.625 │
│ 0.75 0.875 1.0 │
└ ┘Create matrex of ones of square dimensions or consuming output of size/1 function.
iex> Matrex.ones(3)
#Matrex[3×3]
┌ ┐
│ 1.0 1.0 1.0 │
│ 1.0 1.0 1.0 │
│ 1.0 1.0 1.0 │
└ ┘
iex> m = Matrex.new("1 2 3; 4 5 6")
#Matrex[2×3]
┌ ┐
│ 1.0 2.0 3.0 │
│ 4.0 5.0 6.0 │
└ ┘
iex> Matrex.ones(Matrex.size(m))
#Matrex[2×3]
┌ ┐
│ 1.0 1.0 1.0 │
│ 1.0 1.0 1.0 │
└ ┘Create matrix filled with ones.
iex> Matrex.ones(2, 3)
#Matrex[2×3]
┌ ┐
│ 1.0 1.0 1.0 │
│ 1.0 1.0 1.0 │
└ ┘Prints matrix to the console.
Accepted options:
:rows — number of rows of matrix to show. Defaults to 21
:columns — number of columns of matrix to show. Defaults to maximum number of column,
that fits into current terminal width.
Returns the matrix itself, so can be used in pipes.
## Example
iex> print(m, rows: 5, columns: 3) #Matrex[20×20] ┌ ┐ │ 1.0 399.0 … 20.0 │ │ 380.0 22.0 … 361.0 │ │ 360.0 42.0 … 341.0 │ │ ⋮ ⋮ … ⋮ │ │ 40.0 362.0 … 21.0 │ │ 381.0 19.0 … 400.0 │ └ ┘
Create square matrix of random floats.
See random/2 for details.
iex> Matrex.random(3)
#Matrex[3×3]
┌ ┐
│ 0.66438 0.31026 0.98602 │
│ 0.82127 0.04701 0.13278 │
│ 0.96935 0.70772 0.98738 │
└ ┘Create matrix of random floats in [0, 1] range. NIF.
C language RNG is seeded on NIF libray load with srandom(time(NULL) + clock()).
iex> Matrex.random(4,3)
#Matrex[4×3]
┌ ┐
│ 0.32994 0.28736 0.88012 │
│ 0.51782 0.68608 0.29976 │
│ 0.52953 0.9071 0.26743 │
│ 0.82189 0.59311 0.8451 │
└ ┘Reshapes list of values into a matrix of given size or changes the shape of existing matrix.
Takes a list or anything, that implements Enumerable.to_list/1.
Can take a list of matrices and concatenate them into one big matrix.
Raises ArgumentError if list size and given shape do not match.
iex> [1, 2, 3, 4, 5, 6] |> Matrex.reshape(2, 3)
#Matrex[2×3]
┌ ┐
│ 1.0 2.0 3.0 │
│ 4.0 5.0 6.0 │
└ ┘
iex> Matrex.reshape([Matrex.zeros(2), Matrex.ones(2),
...> Matrex.fill(3, 2, 2.0), Matrex.fill(3, 2, 3.0)], 2, 2)
#Matrex[5×4]
┌ ┐
│ 0.0 0.0 1.0 1.0 │
│ 0.0 0.0 1.0 1.0 │
│ 2.0 2.0 3.0 3.0 │
│ 2.0 2.0 3.0 3.0 │
│ 2.0 2.0 3.0 3.0 │
└ ┘
iex> Matrex.reshape(1..6, 2, 3)
#Matrex[2×3]
┌ ┐
│ 1.0 2.0 3.0 │
│ 4.0 5.0 6.0 │
└ ┘
iex> Matrex.new("1 2 3; 4 5 6") |> Matrex.reshape(3, 2)
#Matrex[3×2]
┌ ┐
│ 1.0 2.0 │
│ 3.0 4.0 │
│ 5.0 6.0 │
└ ┘Resize matrix by scaling its dimenson with scale. NIF.
iex> m = Matrex.magic(3)
#Matrex[3×3]
┌ ┐
│ 8.0 1.0 6.0 │
│ 3.0 5.0 7.0 │
│ 4.0 9.0 2.0 │
└ ┘
iex(3)> Matrex.resize(m, 2)
#Matrex[6×6]
┌ ┐
│ 8.0 8.0 1.0 1.0 6.0 6.0 │
│ 8.0 8.0 1.0 1.0 6.0 6.0 │
│ 3.0 3.0 5.0 5.0 7.0 7.0 │
│ 3.0 3.0 5.0 5.0 7.0 7.0 │
│ 4.0 4.0 9.0 9.0 2.0 2.0 │
│ 4.0 4.0 9.0 9.0 2.0 2.0 │
└ ┘
iex(4)> m = Matrex.magic(5)
#Matrex[5×5]
┌ ┐
│ 16.0 23.0 5.0 7.0 14.0 │
│ 22.0 4.0 6.0 13.0 20.0 │
│ 3.0 10.0 12.0 19.0 21.0 │
│ 9.0 11.0 18.0 25.0 2.0 │
│ 15.0 17.0 24.0 1.0 8.0 │
└ ┘
iex(5)> Matrex.resize(m, 0.5)
#Matrex[3×3]
┌ ┐
│ 16.0 23.0 7.0 │
│ 22.0 4.0 13.0 │
│ 9.0 11.0 25.0 │
└ ┘Get row of matrix as matrix (vector) in matrex form. One-based.
You can use shorter matrex[n] syntax for the same result.
iex> m = Matrex.magic(5)
#Matrex[5×5]
┌ ┐
│ 16.0 23.0 5.0 7.0 14.0 │
│ 22.0 4.0 6.0 13.0 20.0 │
│ 3.0 10.0 12.0 19.0 21.0 │
│ 9.0 11.0 18.0 25.0 2.0 │
│ 15.0 17.0 24.0 1.0 8.0 │
└ ┘
iex> Matrex.row(m, 4)
#Matrex[1×5]
┌ ┐
│ 9.0 11.0 18.0 25.0 2.0 │
└ ┘
iex> m[4]
#Matrex[1×5]
┌ ┐
│ 9.0 11.0 18.0 25.0 2.0 │
└ ┘Return matrix row as list by one-based index.
iex> m = Matrex.magic(5)
#Matrex[5×5]
┌ ┐
│ 16.0 23.0 5.0 7.0 14.0 │
│ 22.0 4.0 6.0 13.0 20.0 │
│ 3.0 10.0 12.0 19.0 21.0 │
│ 9.0 11.0 18.0 25.0 2.0 │
│ 15.0 17.0 24.0 1.0 8.0 │
└ ┘
iex> Matrex.row_to_list(m, 3)
[3.0, 10.0, 12.0, 19.0, 21.0]Saves matrex into file.
Binary (.mtx) and CSV formats are supported currently.
Format is defined by the extension of the filename.
iex> Matrex.random(5) |> Matrex.save("r.mtx")
:okTransfer one-element matrix to a scalar value.
Differently from first/1 will not match and throw an error,
if matrix contains more than one element.
iex> Matrex.new([[1.234]]) |> Matrex.scalar()
1.234
iex> Matrex.new([[0]]) |> Matrex.divide(0) |> Matrex.scalar()
:nan
iex> Matrex.new([[1.234, 5.678]]) |> Matrex.scalar()
** (FunctionClauseError) no function clause matching in Matrex.scalar/1Set element of matrix at the specified position (one-based) to new value.
iex> m = Matrex.ones(3)
#Matrex[3×3]
┌ ┐
│ 1.0 1.0 1.0 │
│ 1.0 1.0 1.0 │
│ 1.0 1.0 1.0 │
└ ┘
iex> m = Matrex.set(m, 2, 2, 0)
#Matrex[3×3]
┌ ┐
│ 1.0 1.0 1.0 │
│ 1.0 0.0 1.0 │
│ 1.0 1.0 1.0 │
└ ┘
iex> m = Matrex.set(m, 3, 2, :neg_inf)
#Matrex[3×3]
┌ ┐
│ 1.0 1.0 1.0 │
│ 1.0 0.0 1.0 │
│ 1.0 -∞ 1.0 │
└ ┘Set column of a matrix to the values from the given 1-column matrix. NIF.
iex> m = Matrex.reshape(1..6, 3, 2)
#Matrex[3×2]
┌ ┐
│ 1.0 2.0 │
│ 3.0 4.0 │
│ 5.0 6.0 │
└ ┘
iex> Matrex.set_column(m, 2, Matrex.new("7; 8; 9"))
#Matrex[3×2]
┌ ┐
│ 1.0 7.0 │
│ 3.0 8.0 │
│ 5.0 9.0 │
└ ┘Return size of matrix as {rows, cols}
iex> m = Matrex.random(2,3)
#Matrex[2×3]
┌ ┐
│ 0.69745 0.23668 0.36376 │
│ 0.63423 0.29651 0.22844 │
└ ┘
iex> Matrex.size(m)
{2, 3}Produces element-wise squared matrix. NIF through multiply/4.
iex> m = Matrex.new("1 2 3; 4 5 6")
#Matrex[2×3]
┌ ┐
│ 1.0 2.0 3.0 │
│ 4.0 5.0 6.0 │
└ ┘
iex> Matrex.square(m)
#Matrex[2×3]
┌ ┐
│ 1.0 4.0 9.0 │
│ 16.0 25.0 36.0 │
└ ┘Returns submatrix for a given matrix. NIF.
Rows and columns ranges are inclusive and one-based.
iex> m = Matrex.new("1 2 3; 4 5 6; 7 8 9")
#Matrex[3×3]
┌ ┐
│ 1.0 2.0 3.0 │
│ 4.0 5.0 6.0 │
│ 7.0 8.0 9.0 │
└ ┘
iex> Matrex.submatrix(m, 2..3, 2..3)
#Matrex[2×2]
┌ ┐
│ 5.0 6.0 │
│ 8.0 9.0 │
└ ┘Subtracts two matrices or matrix from scalar element-wise. NIF.
Raises ErlangError if matrices’ sizes do not match.
iex> Matrex.new([[1, 2, 3], [4, 5, 6]]) |>
...> Matrex.subtract(Matrex.new([[5, 2, 1], [3, 4, 6]]))
#Matrex[2×3]
┌ ┐
│ -4.0 0.0 2.0 │
│ 1.0 1.0 0.0 │
└ ┘
iex> Matrex.subtract(1, Matrex.new([[1, 2, 3], [4, 5, 6]]))
#Matrex[2×3]
┌ ┐
│ 0.0 -1.0 -2.0 │
│ -3.0 -4.0 -5.0 │
└ ┘Subtracts the second matrix or scalar from the first. Inlined.
Raises ErlangError if matrices’ sizes do not match.
iex> Matrex.new([[1, 2, 3], [4, 5, 6]]) |>
...> Matrex.subtract_inverse(Matrex.new([[5, 2, 1], [3, 4, 6]]))
#Matrex[2×3]
┌ ┐
│ 4.0 0.0 -2.0 │
│ -1.0 -1.0 0.0 │
└ ┘
iex> Matrex.eye(3) |> Matrex.subtract_inverse(1)
#Matrex[3×3]
┌ ┐
│ 0.0 1.0 1.0 │
│ 1.0 0.0 1.0 │
│ 1.0 1.0 0.0 │
└ ┘Sums all elements. NIF.
Can return special float values as atoms.
iex> m = Matrex.magic(3)
#Matrex[3×3]
┌ ┐
│ 8.0 1.0 6.0 │
│ 3.0 5.0 7.0 │
│ 4.0 9.0 2.0 │
└ ┘
iex> Matrex.sum(m)
45.0
iex> m = Matrex.new("1 Inf; 2 3")
#Matrex[2×2]
┌ ┐
│ 1.0 ∞ │
│ 2.0 3.0 │
└ ┘
iex> sum(m)
:infConvert any matrix m×n to a column matrix (m*n)×1.
iex> m = Matrex.magic(3)
#Matrex[3×3]
┌ ┐
│ 8.0 1.0 6.0 │
│ 3.0 5.0 7.0 │
│ 4.0 9.0 2.0 │
└ ┘
iex> Matrex.to_column(m)
#Matrex[1×9]
┌ ┐
│ 8.0 1.0 6.0 3.0 5.0 7.0 4.0 9.0 2.0 │
└ ┘Converts to flat list. NIF.
iex> m = Matrex.magic(3)
#Matrex[3×3]
┌ ┐
│ 8.0 1.0 6.0 │
│ 3.0 5.0 7.0 │
│ 4.0 9.0 2.0 │
└ ┘
iex> Matrex.to_list(m)
[8.0, 1.0, 6.0, 3.0, 5.0, 7.0, 4.0, 9.0, 2.0]Converts to list of lists. NIF.
iex> m = Matrex.magic(3)
#Matrex[3×3]
┌ ┐
│ 8.0 1.0 6.0 │
│ 3.0 5.0 7.0 │
│ 4.0 9.0 2.0 │
└ ┘
iex> Matrex.to_list_of_lists(m)
[[8.0, 1.0, 6.0], [3.0, 5.0, 7.0], [4.0, 9.0, 2.0]]
iex> r = Matrex.divide(Matrex.eye(3), Matrex.zeros(3))
#Matrex[3×3]
┌ ┐
│ ∞ NaN NaN │
│ NaN ∞ NaN │
│ NaN NaN ∞ │
└ ┘
iex> Matrex.to_list_of_lists(r)
[[:inf, :nan, :nan], [:nan, :inf, :nan], [:nan, :nan, :inf]]Convert any matrix m×n to a row matrix 1×(m*n).
iex> m = Matrex.magic(3)
#Matrex[3×3]
┌ ┐
│ 8.0 1.0 6.0 │
│ 3.0 5.0 7.0 │
│ 4.0 9.0 2.0 │
└ ┘
iex> Matrex.to_row(m)
#Matrex[1×9]
┌ ┐
│ 8.0 1.0 6.0 3.0 5.0 7.0 4.0 9.0 2.0 │
└ ┘Transposes a matrix. NIF.
iex> m = Matrex.new([[1,2,3],[4,5,6]])
#Matrex[2×3]
┌ ┐
│ 1.0 2.0 3.0 │
│ 4.0 5.0 6.0 │
└ ┘
iex> Matrex.transpose(m)
#Matrex[3×2]
┌ ┐
│ 1.0 4.0 │
│ 2.0 5.0 │
│ 3.0 6.0 │
└ ┘Updates the element at the given position in matrix with function.
Function is invoked with the current element value
iex> m = Matrex.reshape(1..6, 3, 2)
#Matrex[3×2]
┌ ┐
│ 1.0 2.0 │
│ 3.0 4.0 │
│ 5.0 6.0 │
└ ┘
iex> Matrex.update(m, 2, 2, fn x -> x * x end)
#Matrex[3×2]
┌ ┐
│ 1.0 2.0 │
│ 3.0 16.0 │
│ 5.0 6.0 │
└ ┘Create square matrix of size size rows × size columns, filled with zeros. Inlined.
iex> Matrex.zeros(3)
#Matrex[3×3]
┌ ┐
│ 0.0 0.0 0.0 │
│ 0.0 0.0 0.0 │
│ 0.0 0.0 0.0 │
└ ┘
![]()


Fast matrix manipulation library for Elixir implemented in C native code with highly optimized CBLAS sgemm() used for matrix multiplication.
For example, vectorized linear regression is about 13 times faster, than Octave single threaded implementation.
It’s also memory efficient, so you can work with large matrices, about billion of elements in size.
Based on matrix code from https://github.com/sdwolfz/exlearn
2015 MacBook Pro, 2.2 GHz Core i7, 16 GB RAM
Operations are performed on 3000×3000 matrices filled with random numbers.
You can run benchmarks from the /bench folder with python numpy_bench.py and MIX_ENV=bench mix bench commands.
benchmark iterations average time
np.divide(A, B) 30 15.43 ms/op
np.add(A, B) 100 14.62 ms/op
sigmoid(A) 50 93.28 ms/op
np.dot(A, B) 10 196.57 ms/opbenchmark iterations average time
divide(A, B) 200 7.32 ms/op (~ 2× faster)
add(A, B) 200 7.71 ms/op (~ 2× faster)
sigmoid(A) 20 71.47 ms/op (23% faster)
dot(A, B) 10 213.31 ms/op (8% slower)Slaughter of the innocents, actually.
2015 MacBook Pro, 2.2 GHz Core i7, 16 GB RAM
Dot product of 500×500 matrices
| Library | Ops/sec | Compared to Matrex |
|---|---|---|
| Matrex | 674.70 | |
| Matrix | 0.0923 | 7 312.62× slower |
| Numexy | 0.0173 | 38 906.14× slower |
| ExMatrix | 0.0129 | 52 327.40× slower |
Dot product of 3×3 matrices
| Library | Ops/sec | Compared to Matrex |
|---|---|---|
| Matrex | 3624.36 K |
| GraphMath | 1310.16 K | 2.77x slower | |
| Matrix | 372.58 K | 9.73x slower | |
| Numexy | 89.72 K | 40.40x slower | |
| ExMatrix | 35.76 K | 101.35x slower |
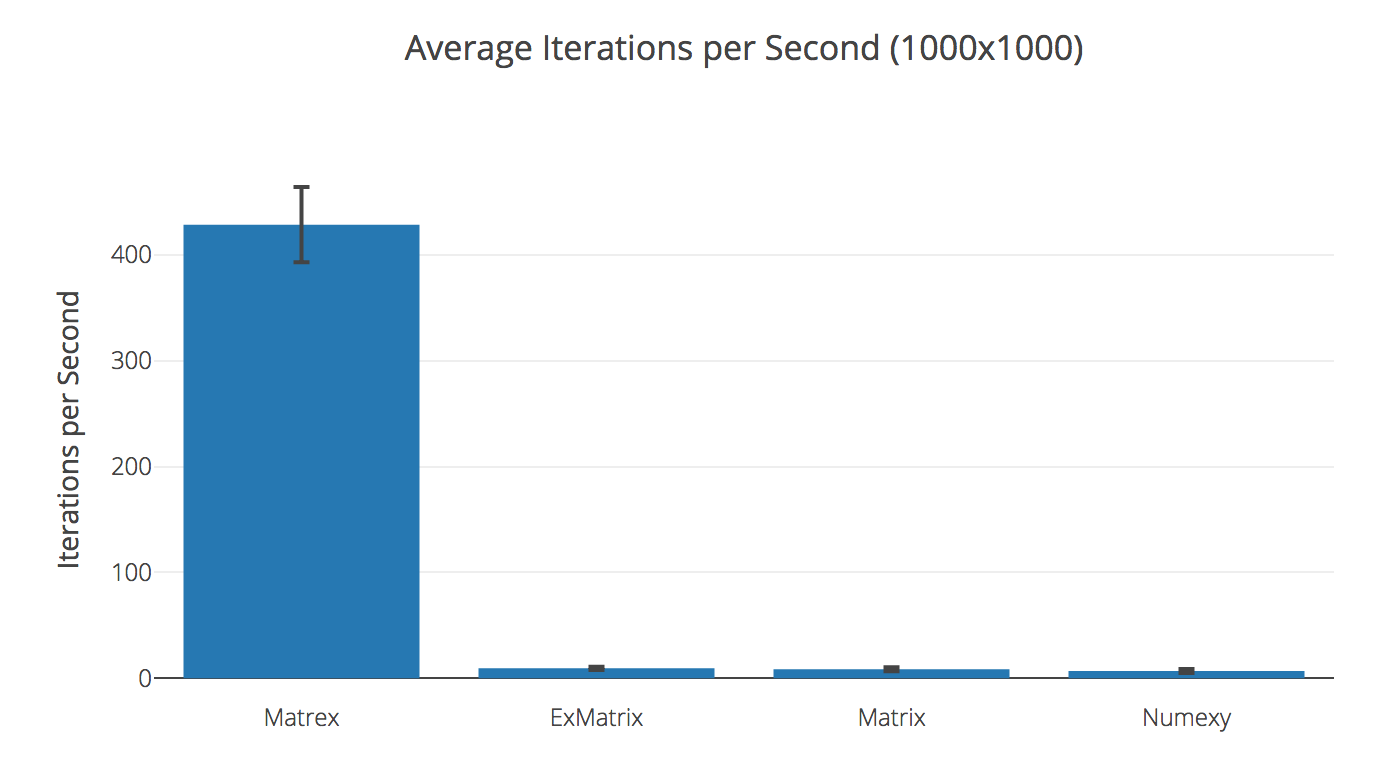
Transposing 1000x1000 matrix
| Library | Ops/sec | Compared to Matrex |
|---|---|---|
| Matrex | 428.69 | |
| ExMatrix | 9.39 | 45.64× slower |
| Matrix | 8.54 | 50.17× slower |
| Numexy | 6.83 | 62.80× slower |
Complete example of Matrex library at work: Linear regression on MNIST digits (Jupyter notebook)
Matrex implements Inspect protocol and looks nice in your console:
It can even draw a heatmap of your matrix in console! Here is an animation of logistic regression training with Matrex library and some matrix heatmaps:
The package can be installed
by adding matrex to your list of dependencies in mix.exs:
def deps do
[
{:matrex, "~> 0.6"}
]
endEverything works out of the box, thanks to Accelerate framework.
You need to install scientific libraries for this package to compile:
> sudo apt-get install build-essential erlang-dev libatlas-base-devIt will definitely work on Windows, but we need a makefile and installation instruction. Please, contribute.
With the help of MATREX_BLAS environment variable you can choose which BLAS library to link with.
It can take values blas (the default), atlas, openblas or noblas.
The last option means that you compile C code without any external dependencies, so, it should work anywhere with a C compiler place:
$ mix clean
$ MATREX_BLAS=noblas mix compileAccess behaviour is partly implemented for Matrex, so you can do:
iex> m = Matrex.magic(3)
#Matrex[3×3]
┌ ┐
│ 8.0 1.0 6.0 │
│ 3.0 5.0 7.0 │
│ 4.0 9.0 2.0 │
└ ┘
iex> m[2][3]
7.0Or even:
iex> m[1..2]
#Matrex[2×3]
┌ ┐
│ 8.0 1.0 6.0 │
│ 3.0 5.0 7.0 │
└ ┘There are also several shortcuts for getting dimensions of matrix:
iex> m[:rows]
3
iex> m[:size]
{3, 3}calculating maximum value of the whole matrix:
iex> m[:max]
9.0or just one of it’s rows:
iex> m[2][:max]
7.0calculating one-based index of the maximum element for the whole matrix:
iex> m[:argmax]
8and a row:
iex> m[2][:argmax]
3Matrex.Operators module redefines Kernel math operators (+, -, *, / <|>) and
defines some convenience functions, so you can write calculations code in more natural way.
It should be used with great caution. We suggest using it only inside specific functions
and only for increased readability, because using Matrex module functions, especially
ones which do two or more operations at one call, are 2-3 times faster.
def lr_cost_fun_ops(%Matrex{} = theta, { %Matrex{} = x, %Matrex{} = y, lambda } = _params)
when is_number(lambda) do
# Turn off original operators
import Kernel, except: [-: 1, +: 2, -: 2, *: 2, /: 2, <|>: 2]
import Matrex.Operators
import Matrex
m = y[:rows]
h = sigmoid(x * theta)
l = ones(size(theta)) |> set(1, 1, 0.0)
j = (-t(y) * log(h) - t(1 - y) * log(1 - h) + lambda / 2 * t(l) * pow2(theta)) / m
grad = (t(x) * (h - y) + (theta <|> l) * lambda) / m
{scalar(j), grad}
endThe same function, coded with module methods calls (2.5 times faster):
def lr_cost_fun(%Matrex{} = theta, { %Matrex{} = x, %Matrex{} = y, lambda } = _params)
when is_number(lambda) do
m = y[:rows]
h = Matrex.dot_and_apply(x, theta, :sigmoid)
l = Matrex.ones(theta[:rows], theta[:cols]) |> Matrex.set(1, 1, 0)
regularization =
Matrex.dot_tn(l, Matrex.square(theta))
|> Matrex.scalar()
|> Kernel.*(lambda / (2 * m))
j =
y
|> Matrex.dot_tn(Matrex.apply(h, :log), -1)
|> Matrex.subtract(
Matrex.dot_tn(
Matrex.subtract(1, y),
Matrex.apply(Matrex.subtract(1, h), :log)
)
)
|> Matrex.scalar()
|> (fn
:nan -> :nan
x -> x / m + regularization
end).()
grad =
x
|> Matrex.dot_tn(Matrex.subtract(h, y))
|> Matrex.add(Matrex.multiply(theta, l), 1.0, lambda)
|> Matrex.divide(m)
{j, grad}
endMatrex implements Enumerable, so, all kinds of Enum functions are applicable:
iex> Enum.member?(m, 2.0)
true
iex> Enum.count(m)
9
iex> Enum.sum(m)
45For functions, that exist both in Enum and in Matrex it’s preferred to use Matrex
version, beacuse it’s usually much, much faster. I.e., for 1 000 x 1 000 matrix Matrex.sum/1
and Matrex.to_list/1 are 438 and 41 times faster, respectively, than their Enum counterparts.
You can save/load matrix with native binary file format (extra fast) and CSV (slow, especially on large matrices).
Matrex CSV format is compatible with GNU Octave CSV output, so you can use it to exchange data between two systems.
iex> Matrex.random(5) |> Matrex.save("rand.mtx")
:ok
iex> Matrex.load("rand.mtx")
#Matrex[5×5]
┌ ┐
│ 0.05624 0.78819 0.29995 0.25654 0.94082 │
│ 0.50225 0.22923 0.31941 0.3329 0.78058 │
│ 0.81769 0.66448 0.97414 0.08146 0.21654 │
│ 0.33411 0.59648 0.24786 0.27596 0.09082 │
│ 0.18673 0.18699 0.79753 0.08101 0.47516 │
└ ┘
iex> Matrex.magic(5) |> Matrex.divide(Matrex.eye(5)) |> Matrex.save("nan.csv")
:ok
iex> Matrex.load("nan.csv")
#Matrex[5×5]
┌ ┐
│ 16.0 ∞ ∞ ∞ ∞ │
│ ∞ 4.0 ∞ ∞ ∞ │
│ ∞ ∞ 12.0 ∞ ∞ │
│ ∞ ∞ ∞ 25.0 ∞ │
│ ∞ ∞ ∞ ∞ 8.0 │
└ ┘Float special values, like :nan and :inf live well inside matrices,
can be loaded from and saved to files.
But when getting them into Elixir they are transferred to :nan,:inf and :neg_inf atoms,
because BEAM does not accept special values as valid floats.
iex> m = Matrex.eye(3)
#Matrex[3×3]
┌ ┐
│ 1.0 0.0 0.0 │
│ 0.0 1.0 0.0 │
│ 0.0 0.0 1.0 │
└ ┘
iex> n = Matrex.divide(m, Matrex.zeros(3))
#Matrex[3×3]
┌ ┐
│ ∞ NaN NaN │
│ NaN ∞ NaN │
│ NaN NaN ∞ │
└ ┘
iex> n[1][1]
:inf
iex> n[1][2]
:nan